存儲管理的演進 數(shù)據(jù)庫優(yōu)化與大數(shù)據(jù)處理存儲支持服務(wù)
在數(shù)字化浪潮席卷全球的今天,數(shù)據(jù)已成為驅(qū)動企業(yè)發(fā)展的核心生產(chǎn)要素。從傳統(tǒng)的結(jié)構(gòu)化數(shù)據(jù)到如今的非結(jié)構(gòu)化海量數(shù)據(jù)流,如何高效、可靠、經(jīng)濟地管理、處理與存儲數(shù)據(jù),已成為技術(shù)領(lǐng)域的關(guān)鍵課題。本文將圍繞存儲管理、數(shù)據(jù)庫優(yōu)化以及大數(shù)據(jù)處理與存儲支持服務(wù)三個層面,探討其內(nèi)在聯(lián)系與協(xié)同演進。
一、 存儲管理:數(shù)據(jù)存取的基石
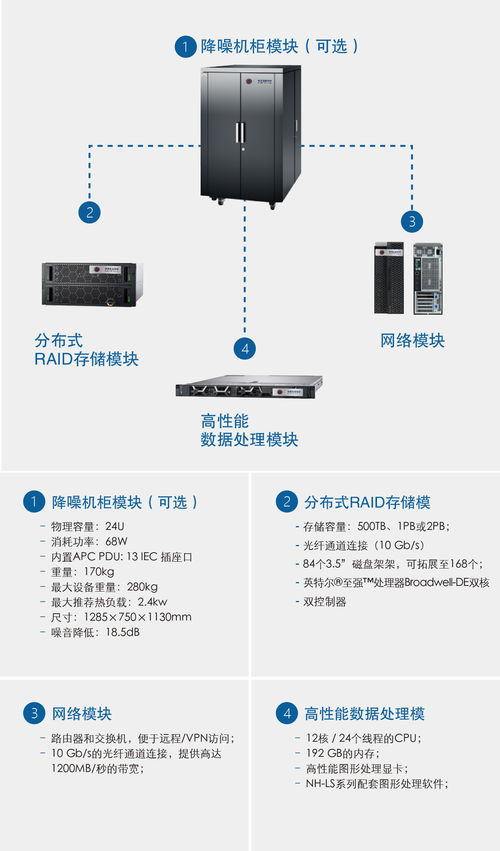
存儲管理是數(shù)據(jù)處理體系的底層基礎(chǔ),其核心目標是確保數(shù)據(jù)的安全性、可用性和高性能存取。傳統(tǒng)存儲架構(gòu),如直接附加存儲(DAS)、網(wǎng)絡(luò)附加存儲(NAS)和存儲區(qū)域網(wǎng)絡(luò)(SAN),主要服務(wù)于結(jié)構(gòu)化數(shù)據(jù)和關(guān)鍵業(yè)務(wù)應(yīng)用。隨著數(shù)據(jù)量的爆炸式增長和數(shù)據(jù)類型的多樣化,現(xiàn)代存儲管理正朝著軟件定義存儲(SDS)、超融合基礎(chǔ)設(shè)施(HCI)和云存儲方向發(fā)展。這些技術(shù)通過抽象化硬件資源,實現(xiàn)了更高的靈活性、可擴展性和成本效益,為上層的數(shù)據(jù)處理應(yīng)用提供了堅實、彈性的支撐平臺。
二、 數(shù)據(jù)庫優(yōu)化:提升核心業(yè)務(wù)效能
數(shù)據(jù)庫作為存儲和管理結(jié)構(gòu)化數(shù)據(jù)的核心系統(tǒng),其性能直接關(guān)系到業(yè)務(wù)應(yīng)用的響應(yīng)速度和用戶體驗。數(shù)據(jù)庫優(yōu)化是一個系統(tǒng)工程,涵蓋多個層面:
1. 架構(gòu)設(shè)計優(yōu)化:合理的表結(jié)構(gòu)設(shè)計、索引策略(如B樹、位圖索引)以及范式與反范式的權(quán)衡,能從根源上提升查詢效率。
2. 查詢優(yōu)化:通過分析執(zhí)行計劃、重寫低效SQL語句、利用查詢提示或優(yōu)化器引導(dǎo),減少不必要的全表掃描和連接操作。
3. 資源配置優(yōu)化:根據(jù)工作負載特性,調(diào)整內(nèi)存分配(如緩沖池、排序區(qū))、I/O配置以及并發(fā)連接數(shù),確保數(shù)據(jù)庫引擎高效運行。
4. 高可用與擴展優(yōu)化:采用主從復(fù)制、分庫分表、讀寫分離乃至新型的分布式數(shù)據(jù)庫架構(gòu),以應(yīng)對高并發(fā)訪問和海量數(shù)據(jù)存儲挑戰(zhàn)。
優(yōu)化的本質(zhì)是在有限的存儲與計算資源下,讓數(shù)據(jù)庫系統(tǒng)以最高的效率服務(wù)于業(yè)務(wù)邏輯。
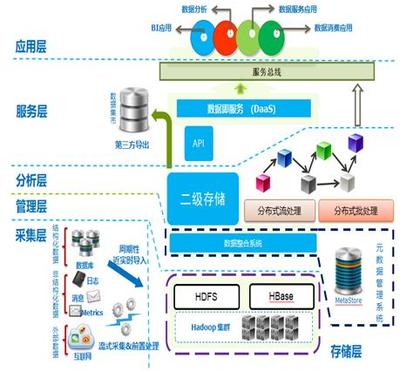
三、 大數(shù)據(jù)處理與存儲支持服務(wù):應(yīng)對規(guī)模化挑戰(zhàn)
當(dāng)數(shù)據(jù)規(guī)模、速度和多樣性超出傳統(tǒng)數(shù)據(jù)庫的舒適區(qū)時,便進入了大數(shù)據(jù)領(lǐng)域。大數(shù)據(jù)處理涉及批處理(如Hadoop MapReduce)、實時流處理(如Apache Flink, Apache Storm)和交互式查詢(如Apache Hive, Presto)等多種模式。這背后離不開新一代存儲支持服務(wù)的支撐:
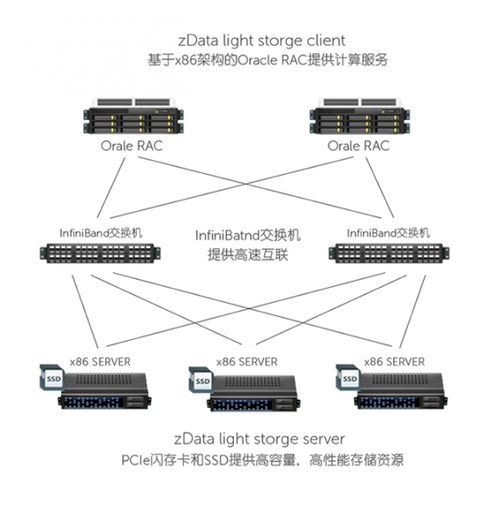
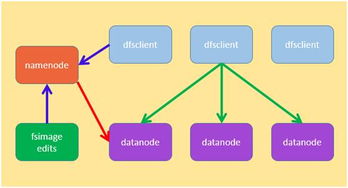
- 分布式文件系統(tǒng):如HDFS、Ceph,它們將海量數(shù)據(jù)分散存儲在低成本服務(wù)器集群上,提供高吞吐量的數(shù)據(jù)訪問能力,是大數(shù)據(jù)生態(tài)的存儲基石。
- NoSQL與NewSQL數(shù)據(jù)庫:如MongoDB(文檔型)、Cassandra(列族型)、Redis(鍵值型)以及TiDB(分布式關(guān)系型),它們針對特定的大數(shù)據(jù)場景(高并發(fā)、半結(jié)構(gòu)化、水平擴展)提供了優(yōu)化的數(shù)據(jù)模型和存儲引擎。
- 數(shù)據(jù)湖與對象存儲:如基于AWS S3、阿里云OSS構(gòu)建的數(shù)據(jù)湖,允許以原始格式存儲海量異構(gòu)數(shù)據(jù)(文本、圖像、日志等),為后續(xù)的探索性分析和機器學(xué)習(xí)提供了靈活的數(shù)據(jù)底座。
- 一體化數(shù)據(jù)平臺服務(wù):云廠商提供的如數(shù)據(jù)倉庫(Snowflake, BigQuery)、數(shù)據(jù)湖分析、流數(shù)據(jù)攝取等托管服務(wù),集成了存儲、計算、管理和分析工具,極大降低了企業(yè)構(gòu)建和維護大數(shù)據(jù)平臺的技術(shù)門檻與成本。
四、 融合與協(xié)同:構(gòu)建一體化數(shù)據(jù)戰(zhàn)略
存儲管理、數(shù)據(jù)庫優(yōu)化與大數(shù)據(jù)服務(wù)并非孤立存在,而是緊密關(guān)聯(lián)、層層遞進。現(xiàn)代數(shù)據(jù)架構(gòu)往往采用混合或多層設(shè)計:
- 將在線事務(wù)處理(OLTP)的核心業(yè)務(wù)數(shù)據(jù)存放在經(jīng)過深度優(yōu)化的關(guān)系型數(shù)據(jù)庫中,確保ACID屬性和低延遲。
- 將歷史數(shù)據(jù)、日志、點擊流等大數(shù)據(jù)量、低價值密度數(shù)據(jù)遷移至數(shù)據(jù)湖或低成本對象存儲中。
- 利用大數(shù)據(jù)處理框架(如Spark)對湖倉中的數(shù)據(jù)進行分析、清洗和轉(zhuǎn)換,結(jié)果可反饋至優(yōu)化后的數(shù)據(jù)庫供業(yè)務(wù)系統(tǒng)使用,或存入專門的分析型數(shù)據(jù)庫(OLAP)支持決策。
- 統(tǒng)一的存儲管理策略和生命周期策略,實現(xiàn)數(shù)據(jù)在熱、溫、冷存儲介質(zhì)間的自動流動,優(yōu)化總體擁有成本(TCO)。
###
從精細化的單機數(shù)據(jù)庫優(yōu)化,到面向海量異構(gòu)數(shù)據(jù)的大規(guī)模分布式處理與存儲,技術(shù)演進的主線始終是圍繞數(shù)據(jù)的價值實現(xiàn)。未來的趨勢將是智能化存儲管理、自治數(shù)據(jù)庫與云原生大數(shù)據(jù)服務(wù)的深度融合。企業(yè)需要根據(jù)自身的業(yè)務(wù)特點、數(shù)據(jù)規(guī)模和成本預(yù)算,制定彈性的、可持續(xù)演進的數(shù)據(jù)架構(gòu),讓存儲、處理與優(yōu)化三者協(xié)同,共同支撐起數(shù)據(jù)驅(qū)動業(yè)務(wù)創(chuàng)新的宏偉藍圖。
最新產(chǎn)品